
Currently reading about “botshit”, and how to avoid it (Hannigan, McCarthy, Spicer; 2024)
When I recently summarized an article that claimed that Large Language Models (LLM) are “bullshit”, I got a lot of strong reactions offline and online about that term, and a comment recommending the article “Beware of botshit: how to manage the epistemic risks of generative chatbots” (Thanks, Ian!). In that article, Hannigan, McCarthy and Spicer (2024) suggest using the term “botshit” to describe what can happen when users uncritically use the output of LLMs, and I spent the better part of a Baltic Sea crossing today enjoying that article.
I really really appreciated reading this article (and also the slide deck summarizing it!), as the authors start out by giving an excellent introduction to how LLMs work, and where the hallucinations actually come in. I have reimagined their table in the figure below (I always have to re-draw things to force myself to think them through, but I am also pretty sure that this figure will come in very handy whenever I need to teach anything related to LLMs again!).
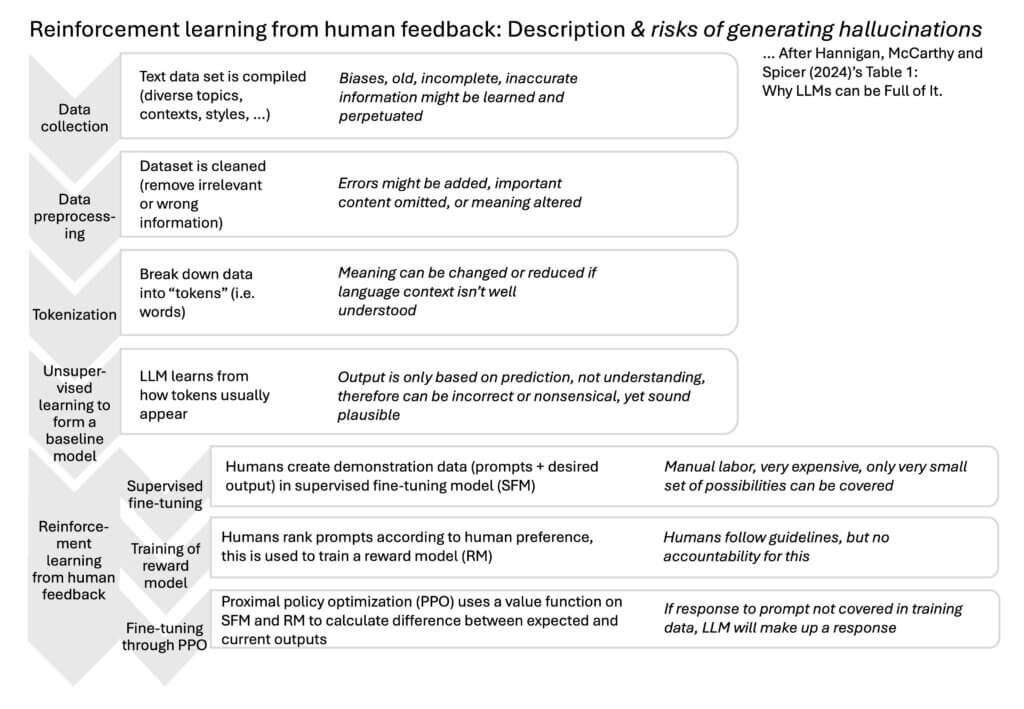
(Btw, I just remembered how I learned about machine learning: Through the game “Chomp!” by Dan Wallace! Check it out if you want a fun and super easy scicomm game!)
In addition to the data input and unsupervised learning of the model in the first four steps, they describe the “Reinforcement Learning from Human Feedback” process used to fine-tune responses in ChatGPT. In this process, humans compare prompts and responses with what they would deem the most desirable response, and thus new rules are created to make sure the output is not just based purely on extrapolation from training data, but matches “human users’ values”. This can be about the format of the output, reducing bias or toxic content, or avoiding fictional information. Humans rank different outputs to train the model towards what they would prefer to see.
It is easy to see how all of these steps can lead to undesirable outputs, hallucinations, for example if the training dataset contains old, faulty, or biased data, or if it is “cleaned” in a way that introduces new problems. But also the human training part can cause problems, for example by introducing values or biases that are misaligned with the final users’ values.
Based on this, the authors “highlight that LLMs are designed to ‘predict’ responses rather than ‘know’ the meaning of these responses. LLMs are likened to ‘stochastic parrots’ (Bender et al., 2021) as they excel at regurgitating learned content without comprehending context or significance.” They produce “a technical word-salad on patterns of words in training data (which is itself a black box)”. There are two types of botshit: Intrinsic botshit is wrong according to the training data, and extrinsic botshit is made-up information that is not supported by training data.
A lot of research has shown that bullshitters, in contrast to liars, have no concern for the truth and just make up stuff, which can then happen to be true — or not. They do it for prestige, to maintain face, out of a workplace culture, where saying anything but using grand words is valued over saying something of substance. Using LLM outputs uncritically, botshitting, is probably done out of similar motivations.
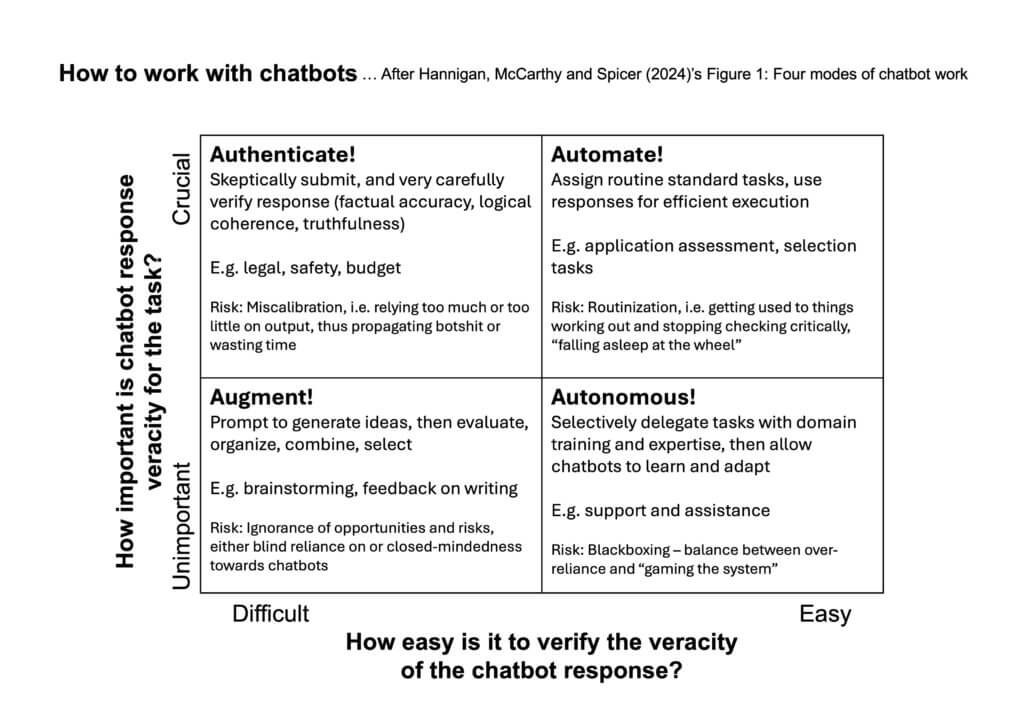
But where does this lead us when we still want to work using LLMs, but in a good way? The authors suggest two questions we need to answer in order to assess the risks of using LLMs for a given task:
- How important is chatbot response veracity for the task? For example, if lives depend on it, trusting a LLM is probably not a good idea. On the other hand, using a LLM to generate ideas or to get feedback on a text is relatively low-risk, since the user most likely will use the the output to further reflect rather than using it as is.
- How easy is it to verify the veracity of the chatbot response? Easy are responses to factual knowledge questions like definitions. But for any real work, creative process, envisioning a future, any question where finding the answer is difficult, it is obviously also difficult to impossible to check whether an answer is correct or trustworthy.
This leads to four different cases (which, of course, as always, are not as distinct in practice as in the framework…), see also figure below:
- Augment! When response veracity is not important and also difficult to check, for example in brainstorming tasks, the user can prompt the LLM to generate ideas and then use output in their creative process where they will still evaluate, organize, select, and combine anyway. One example here is how I worked with Claude on generating my workshop.
- Authenticate! When response veracity is crucial but difficult to check, for example when deciding on high-stakes investments, the user should obviously not rely on outputs but make sure they have measures in place that ensure that any output is critically thought about and outputs only inform rather than dictate decision-making.
- Automate! When response veracity is important but easy to check, for example in routine tasks, any output needs to be sense-checked, but the LLM can take on parts of work flows fairly autonomously.
- Autonomous! When response veracity is not important and easy to check, for example responding to routine FAQs, chatbots can take on tasks autonomously (and I feel like I have spent way too much time trying to talk to such chatbots where I did care a lot more about response veracity than the company did that outsourced that task to a bot…)
I think this is a useful framework to think about how to assess and manage risks.
The next chapter is highly relevant: “Using chatbots with integrity”. The authors identify four main risks that are present in all four modes above, but most strongly associated with one each:
- ignorance for augmented: Users are not sufficiently aware of risks and opportunities of LLMs and therefore fail to use them to their benefit. To counteract this, we could build the LLM into our workflows, e.g. by routinely checking emails before we send them (or Swedish Instagram captions before we post, hi @active.divers!), or by using LLM outputs in the same way as external stakeholder inputs.
- miscalibration for authenticated: Users trust the output too much or not enough, therefore either using it too uncritically or spending too much time on verifying outputs. This can be counteracted by tracking veracity over time and using that to calibrate checking behaviour.
- routinization for automated: If outputs aren’t checked enough, companies might miss that customer questions have changed and that their chatbots do not respond adequately to a new FAQ.
- black boxing for autonomous: If users are not aware what happens inside the LLM black box, they cannot actually assess the risks of using it. Here, the authors suggest creating a version of their table 1 specific for the context, but warn that understanding too much of what is going on inside an LLM might tempt people to game it or misuse it for personal agendas.
Lastly, the authors present a chapter titled “learn to rely on me”. They compare the process of learning to rely on LLMs to the process that occurred when calculators first became available and used in schools, and it was feared that that might destroy students’ maths learning, which turned out to not be the case. The authors present three types of “guardrails” that should be in place and can help mitigate the risks of using chatbots:
- Technology-oriented guardrails would work inside the black box, i.e. would be implemented by the development team, and could for example include cross-checking of outputs with trusted sources like dictionaries
- Organization-oriented guardrails are guidelines and policies inside the organisations that use LLMs, in order to mitigate botshitting. These could be a code of conduct, employee training in the specific context of their tasks, control systems, etc
- User-oriented guardrails encourage a critical mindset, cross-checking, validating, etc., as well as speaking up when things feel wrong, and questioning responses
So far for the summary of this article. Puh! But this was a super useful read.
I am thinking about this mostly in the context of how higher education teaching should deal with LLMs, but also regarding a side-project of mine trying to understand how to use LLMs in Scholarship of Teaching and Learning (SoTL), since this is where I actually need to provide guidance and guidelines. And I think that this article is very helpful for both, both the way that LLMs and the processes behind them are explained, and in the risk assessment and mitigation framework. We might need to think a bit about how we define “risk” in SoTL. It is very unlikely that people will die or be seriously be harmed by a chatbot hallucinating and then a teacher botshitting about teaching and learning. But SoTL is about scholarship, so botshitting rather than following the scientific method does carry the risk of a slippery slope of “oh, I’ll just use it for this, I would never use it for anything serious“, of compromising the integrity of the teachers (who are all researchers, too), and of botshit then being taken and trusted as scholarly results, which they are not and cannot be, and build on by others. So my main interest now is to look further into the organization- and user-oriented guidelines that I think should be in place for using LLMs in SoTL, and to discuss those further. So if you have any ideas, please let’s discuss! :-)
Hannigan, I. P. McCarthy, A. Spicer (2024), Beware of Botshit: How to Manage the Epistemic Risks of Generative Chatbots, Business Horizons, 2024 (I accessed the free pre-print here https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4678265, and a slide deck summarizing the article)